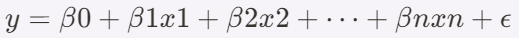이번주는 러닝 머신에 대해 배웠습니다.솔직히 좀 어렵더라구요. 특히 강의에서 나온 코드들은 따로 의미를 알려줄 뿐, 쓰는법, 즉 그 코드의 프레임이 뭔지 정확한 해답이 없었습니다. 그래서 그것을 전부 찾아보는 어려움이 있었습니다. 그런데 솔직히 찾아보면서 재미있기도 했습니다. 새로운것을 찾았다는 느낌과 그것을 새로이 배웠다는 느낌. 확실히 다르긴 하더라구요. 특히 처음 선형회귀를 다시 복습을 하는 과정에서 제가 몰랐던 정보까지 싹다 얻을 수 있어서, 저는 솔직히 만족감이 컸습니다. 하지만 오늘 DBSCAN을 마지막으로(SBSCAN도 약간 덜 들어간) 깊게 파고드는 것을 포기했습니다. 시간이 너무 오래 들었기 때문입니다. 딥 러닝도 배워야 했기에 저는 어쩔 수 없이 기본 개념들만 가지고 딥 러닝을 시작할..