학습 지도에서는 정답을 맞추고, 그것을 AI에게 학습을 시켰다면, 비지도 학습은 정답이 없습니다. 즉, 비지도 학습에서는 입력 데이터만 있고, 이를 통해 데이터의 구조나 패턴을 학습합니다. 주로 데이터를 분류하거나 그룹으로 묶는 데 사용됩니다.
예를 들어 서로 비슷한 데이터끼리 묶어, 한 군집을 만드는 식으로 학습을 합니다.
K-means clustering
K-means clustering이란 주어진 데이터를 여러 개의 클러스터(그룹)로 나누는 알고리즘입니다. 특징 하나하나를 컬럼으로 나타내는데, 이 컬럼을 좌표로 생성해 둔다면, 데이터는 차원에 따라 그림으로 나타낼 수 있는 형태로 나온다. 그리고 그 그림(좌표)형태에서 서로 가까이 있는 것들끼리 군집으로 만드는 것이 K-mean clustering기법입니다.
이제, K-means 클러스터링의 작동 원리에 대해 자세히 알아봅시다. 1. K개의 클러스터 중심 설정: K는 곧 클러스터들의 중심점을 말하고, 그 중심을 기준으로 데이터 포인트들이 서로 비슷한 특성을 가진 클러스터에 할당됩니다. 즉 제가 설정한 K값에 따라, 클러스터의 중심을 나타냅니다.
2. 데이터 할당: 여러개로 분포가 되어있는 데이터 포인트들 중, 중심점에서 가까운으로 할당시켜, 클러스터(그룹)을 형성합니다. 이때 데이터와 중심점 간의 거리는 유클리드 거리(Euclidean distance)를 사용해 측정합니다.
3. 중심점 업데이트: 이제 클러스터를 만들고, 그 안에 속한 데이터들의 평균을 계산해서 새로운 중심점을 설정합니다.
4. 반복: 데이터 포인트가 더 이상 클러스터를 바꾸지 않을 때까지 또는 중심점이 더 이상 변하지 않을 때까지 2번과 3번의 과정을 반복합니다.
단순히 요약하면, 먼저 중심을 설정을 하면 주변에 비슷한 값들이 서로 뭉치게 됩니다. 그리고 곧 그 값과 중심점 사기에 중간 값이 새로운 중간값으로 바뀌게 될 것이고, 다른 값이 또 할당이 되었을 때, 또 새롭게 중간값이 배정되게 됩니다. 그리고 이 과정을 반복하는 것이 핵심입니다.
Tip: 군집의 중심과 데이터 간의 거리를 구하기 위해 유클리드 거리 수식을 사용하는데, 수식은
그런데 K의 값을 지정해줘야 하는데, 솔직히 알기는 힘듭니다. 그렇기에 엘보우 방법을 사용합니다. 엘보우 방법은 최적의 K 값을 찾는데 사용이 됩니다. 예를 들어:
코드를 통해 값을 그래프로 나타냈다면, 이런식으로 나올 겁니다. 그리고 K의 값을 점점 줄이면 결국에는 값의 변화가 거의 없어지는 구간이 올텐데, 보면 k의 값이 4부터 값의 변화가 거의 없어집니다. 그렇다는 건, 최적의 K의 값이 4라는 것을 알 수 있습니다.
이제 그럼 강의에 나온 실습을 진행해 봅시다.
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
# 데이터 로드
data = pd.read_csv('Mall_Customers.csv')
# 필요한 열 선택 및 결측값 처리
data = data[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']]
# 데이터 스케일링
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
# 최적의 k 찾기 (엘보우 방법)
inertia = []
K = range(1, 11)
for k in K:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(data_scaled)
inertia.append(kmeans.inertia_)
# 엘보우 그래프 그리기
plt.figure(figsize=(10, 8))
plt.plot(K, inertia, 'bx-')
plt.xlabel('k')
plt.ylabel('Inertia')
plt.title('Elbow Method For Optimal k')
plt.show()
# k=5로 모델 생성 및 학습
kmeans = KMeans(n_clusters=5, random_state=42)
kmeans.fit(data_scaled)
# 군집 결과 할당
data['Cluster'] = kmeans.labels_
일단 이번에는 새로운것을 가지고 오는 코드입니다. 먼저 from sklearn.cluster import KMeans -> KMeans는 K-means 클러스터링 알고리즘을 사용하기 위한 클래스입니다. K-means는 데이터를 K개의 그룹으로 나누어주는 비지도 학습 기법입니다. import KMeans를 통해 K-means clustering 모델을 쓸 수 있게 됩니다.
import matplotlib.pyplot as plt -> matplotlib.pyplot은 데이터 시각화를 위한 파이썬 라이브러리입니다. 특히 그래프를 그리는 데 많이 사용됩니다. 이 라이브러리를 통해 데이터를 선 그래프, 막대 그래프, 산점도 등 다양한 형태로 시각화할 수 있습니다. 아까 말했던 엘보우 방법을 쓰기 위해서는, 그래프를 통해 최적화 K를 찾아야 하기 때문에, 쓰이고 있습니다.
이제 파일을 꺼내오는데, data = data[['Age', 'Annual Income (k$)', 'Spending Score (1-100)']] 에서 특정한 데이터들만 가져오고 있습니다. 그 이유로는 데이터가 '수치형'이여야만 값을 구할 수 있기 때문입니다. 그렇기에 수치형인 데이터만 가져오는 식입니다.
그러면 이제 inertia = [] K = range(1, 11) for k in K: kmeans = KMeans(n_clusters=k, random_state=42) kmeans.fit(data_scaled) inertia.append(kmeans.inertia_) 이 코드에 대해 설명하겠습니다. 먼저 K에는 1~10까지의 숫자가 들어가됩니다(마지막 숫자 제외) 그리고 이제 for k in K를 써서, 1~10까지의 숫자가 k에 하나씩 들어가게 됩니다. 즉, 10번을 반복하게 된다는 소리입니다. 자, 이제 중요 코드들을 하나하나 보겠습니다. 1. KMeans(n_clusters=k): k 값에 따라 k개의 군집을 만들겠다는 의미입니다. 예를 들어, k=1, k=2, ..., k=10로 각각 K-means 모델을 생성합니다. 따라서 10번을 반복하기에, kmeans = KMeans(n_clusters=1, random_state=42) kmeans = KMeans(n_clusters=2, random_state=42) kmeans = KMeans(n_clusters=3, random_state=42) .......... kmeans = KMeans(n_clusters=10, random_state=42) 이렇게 10개가 만들어지게 됩니다. 단, 알아야 하는것은 10개의 군집이 만들어지는 것이 아니라, 각 군집의 갯수마다 값을 구하는 식이라는 것을 알아야 합니다.
참고로 중요한 점이 있습니다. K가 1~10까지 줬다고 했는데, 1~100, 혹은 1~3은 안될까 라는 생각이 들기도 했습니다. 하지만 k값이 너무 작으면 데이터 분포를 제대로 반영하지 못하고, k값이 너무 크면 군집이 너무 많이 나뉘어 과적합(overfitting)될 수 있기 때문에, 적당히 1~10까지 준것입니다.
2. kmeans.fit(data_scaled) 여기서 궁금증이 하나 생겼습니다. fit은 학습을 시키는 것인데, 어떻게 data_scaled로 학습을 시키는걸까? 답은 바로 사용자가 입력하는 모델에 따라 fit()의 수식도 따라서 바뀐다는 것입니다. 즉, 수식이 달라졌으니 들어가는 값(data_scaled)도 그에 맞는 수식에 들어가 값을 제공 및 학습을 시키는 것입니다. 그렇기에 실제로 kmeans에는 KMeans라는 모델이 들어가 있으며, KMeans 모델에 맞는 수식이 적용(fit)되어 data_scale도 그 수식에 맞게 적용이 되는 것입니다.
그렇게 되면 군집의 중심을 찾는 작업이 시작되고, 그 값이 여기서 끝나는것이 아니라, 그 값을 토대로 .inertia_라는 KMeans의 속성을 통해 관성 값(데이터 포인트들이 군집 중심과 얼마나 가까운지)을 가져옵니다. 그리고 그 값들을 .apppend를 통해 inertia라는 빈 리스트들에 추가가 되는 것임니다. 그리고 이 모든 과정을 총 10번.(1,2,3...10) 진행하여, k가 1일때의 관성 값, k가 2일때의 관성 값....이렇게 총 10개의 값이 들억가게 되는 것입니다. 참고로 UserWarning: KMeans is known to have a memory leak on Windows with MKL, when there are less chunks than available threads. You can avoid it by setting the environment variable OMP_NUM_THREADS=1.라는 에러가 뜨면 Anaconda Prompt에서 set OMP_NUM_THREADS=1 치고 엔터 누르고 다시 실행시키면 됩니다. 그러면 이제 plt.figure(figsize=(10, 8)) plt.plot(K, inertia, 'bx-') plt.xlabel('k') plt.ylabel('Inertia') plt.title('Elbow Method For Optimal k') plt.show() 이 코드들에 대해 알아보겠습니다. 아까 말씀드렸다싶이 plt는 그래프를 만들기위해 쓰입니다. 그리고 K = 1~10일때의 값들이 들어있는 inertia 리스트를 이 그래프에 쓰면, 10개의 값이 그래프의 10개의 점으로 나타나게 됩니다.그리고 그 10개의 점들에게서 직접 최적의 K의 값을 찾는것이 바로 엘보우 방식이다 라고 할 수 있습니다.
먼저, 1. plt.figure(figsize=(10, 8)) ->plt.figure(): 새로운 그래프를 그리기 위한 캔버스(도화지)를 만듭니다. 그리고 figsize=(10, 8) -> 그래프의 크기를 지정합니다. 10x8인치의 크기로 도화지를 설정한 것입니다.( 10: 가로 크기, 8: 세로 크기) (K의 값이 10개 있기때문)
2. plt.plot(K, inertia, 'bx-') -> plt.plot(): 그래프를 그리는 함수입니다 그리고 K:x축에 들어갈 값, 여기서는 **군집의 개수(k)**입니다. inertia: y축에 들어갈 값, 군집의 개수에 따른 관성 값(inertia)입니다. 'bx-': 그래프의 스타일을 지정합니다.(그래프의 색상, 마커(점 모양), 선 스타일) b: 파란색(blue)으로 표시 x:각 점을 x 모양으로 표시 -: 각 점을 선으로 연결
3. plt.xlabel('k') -> plt.xlabel(): x축에 라벨(이름)을 붙입니다 즉, k라는 이름을 x축에 이름을 붙였습니다.
4. plt.ylabel('Inertia') -> plt.ylabel(): y축에 **라벨(이름)**을 붙입니다. 즉, 여기서는 'Inertia'로 설정하여, y축이 관성 값(Inertia)임을 나타냅니다.
5. plt.title('Elbow Method For Optimal k') -> plt.title(): 그래프 전체의 제목을 설정합니다. 여기서는 엘보우 방법을 사용해 최적의 k를 찾는 과정임을 나타내는 제목을 설정했습니다.
6. plt.show() -> plt.show(): 그래프를 화면에 표시합니다. 이 명령이 호출되면, 지금까지 설정된 내용들이 화면에 그래프로 출력됩니다. 그러면 이렇게 값이 출력이 됩니다. 이제 이 그래프에서 최적의 K를 찾는 것 입니다. 찾는 법은 간단합니다. 값이 줄어들수록, 관성값의 변화가 거의 없어지는 구간을 찾으면 됩니다. 여기서는 5부터 x의(점) 간격의 변화가 없기에 최적의 K는 5라는 것을 알 수 있습니다.
이제 K가 5라는 것을 알았으니 이것을 다시 학습 시키면 됩니다. # k=5로 모델 생성 및 학습 kmeans = KMeans(n_clusters=5, random_state=42) kmeans.fit(data_scaled)
# 군집 결과 할당 data['Cluster'] = kmeans.labels_
1. KMeans(...) -> 이 방법을 통해 KMeans 클러스터링 모델을 초기화합니다.
2. n_clusters=5- > 클러스터의 개수를 5로 설정합니다. 즉, 이 모델은 데이터를 5개의 클러스터로 그룹화합니다.
3. fit(data_scaled) -> 그리고 다시 한번 전처리된 데이터(data_scaled)를 사용하여 모델을 학습합니다.
4. kmeans.labels_ -> 각 데이터 포인트가 할당된 클러스터의 레이블을 반환합니다.
5. data['Cluster'] -> data DataFrame에 새로운 열을 추가합니다. 이 열의 이름은 Cluster'이며, 각 데이터 포인트가 속한 클러스터의 레이블을 저장합니다.
그럼 이제 군집을 시각화 시켜보겠습니다.
# 2차원으로 군집 시각화 (연령 vs 소득)
plt.figure(figsize=(10, 8))
sns.scatterplot(x=data['Age'], y=data['Annual Income (k$)'],
hue=data['Cluster'], palette='viridis')
plt.title('Clusters of customers (Age vs Annual Income)')
plt.show()
# 2차원으로 군집 시각화 (소득 vs 지출 점수)
plt.figure(figsize=(10, 8))
sns.scatterplot(x=data['Annual Income (k$)'], y=data['Spending Score (1-100)'],
hue=data['Cluster'], palette='viridis')
plt.title('Clusters of customers (Annual Income vs Spending Score)')
plt.show()
여기서 핵심줄만 설명하겠습니다. sns.scatterplot(x=data['Age'], y=data['Annual Income (k$)'], hue=data['Cluster'], palette='viridis') 1. sns.scatterplot(...): Seaborn의 scatterplot 함수를 사용하여 산점도를 그립니다. 2. x=data['Age']: x축에 'Age' 열의 데이터를 사용합니다. 3. y=data['Annual Income (k$)']: y축에 'Annual Income (k$)' 열의 데이터를 사용합니다. 4. hue=data['Cluster']: 데이터 포인트의 색상을 'Cluster' 열의 값에 따라 다르게 표시합니다. 같은 군집에 속하는 데이터 포인트는 같은 색상으로 표시됩니다. 5. palette='viridis': 색상 팔레트를 'viridis'로 설정하여 색상이 연속적으로 변하게 합니다.
계층적 군집화
군집화 모델중, 계층적 군집화는 데이터를 계층적으로 그룹화하는 방법으로, 두가지 방법이 있는데, 하나는 병합 군집화와 분할 군집화가 있습니다. 1. 병합 군집화 -> 쉽게 말해서, 데이터 포인트들이 개별 군집으로 시작하여, 서로 뭉쳐지는 스타일 입니다. 서로 간 개별 군집이었다가, 서로 가장 가까군 군집을 반복적으로 병합하는 식입니다. 2. 분할 군집화 -> 처음에는 모든 데이터 포인트들이 하나의 군집으로 시작하여, 개별적으로 쪼개지는 스타일입니다. 즉, 하나의 군집이였다가, 가장 멀리 떨어진 군집들을 분할하면서 나중에 개별적 군집으로 만들어지는 겁니다. 하지만 분할 군집화는 사용하기 까다로워 잘 쓰이지 않습니다.
그렇기에 병합적 군집화의 주요 단계만 보겠습니다.
거리 계산: 데이터를 비교하기 위해 각 데이터 포인트 간의 거리를 계산합니다. 유클리드 거리(Euclidean Distance)와 같은 방법을 사용합니다.
클러스터 병합: 가장 가까운 두 클러스터를 병합하여 새로운 클러스터를 만듭니다.
반복: 클러스터가 하나만 남을 때까지 이 과정을 반복합니다.
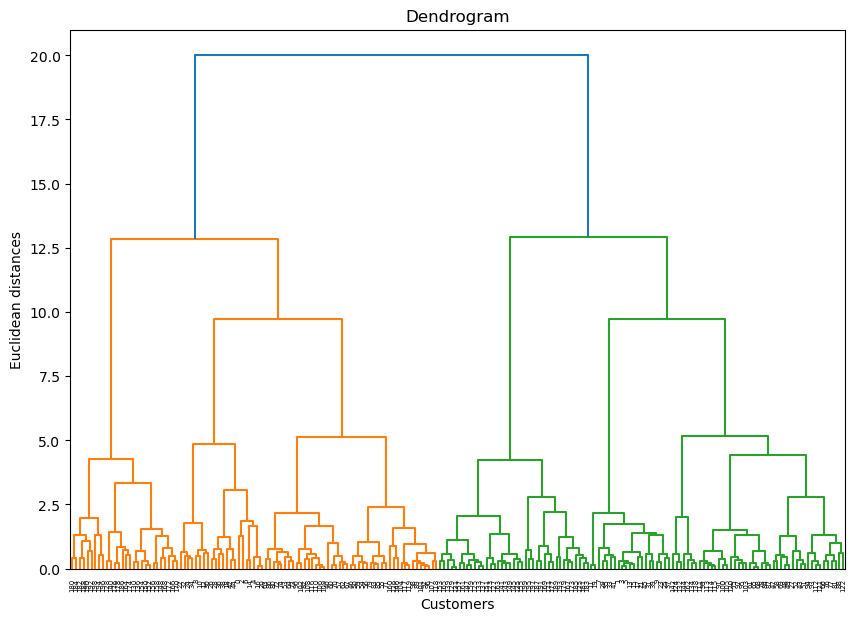
덴드로그램 해석: 덴드로그램에서 수직선이 연결되는 높이는 클러스터 간의 거리를 나타내며, 원하는 클러스터 수에 맞춰 최적의 그룹을 선택할 수 있습니다.
잠깐, 여기서 덴드로그램 해석이란? 덴드로그램 해석이란, 트리 구조의 클러스터 병합 순서를 보고, 데이터를 어떻게 그룹화할지 결정하는 과정입니다. K-Means Clustering에서 엘보우 방법과 비슷한 방식으로, 그래프를 보고 클러스터의 수를 지정해야 합니다. 그리고 그 수를 결정하려면 덴드로그램의 수평선 위치를 보고, 가장 긴 수평선을 기준으로 적절한 클러스터 수를 선택할 수 있습니다.
덴드로그램의 주요 구성 요소: 1. 수직선(Branches): 덴드로그램에서 수직선은 각각의 데이터를 나타내고, 클러스터 간의 유사도를 표현합니다. 두 개의 데이터(또는 클러스터)가 만나는 지점이 병합된 지점입니다. 예를 들어, 데이터 포인트 두 개가 가까울수록 덴드로그램에서 그 지점이 아래쪽에 나타납니다.
2. 수평선(Height): 덴드로그램에서 클러스터 간의 병합이 이루어질 때, 수평선이 그려집니다. 이 수평선의 높이는 두 클러스터 간의 거리를 나타냅니다. 거리가 짧을수록(높이가 낮을수록) 두 클러스터가 더 유사하다는 뜻입니다.
3. 클러스터의 개수:
덴드로그램에서
클러스터를 나누는 기준을 설정할 수 있습니다. 트리의 어느 높이에서 수평선을 그으면, 그 아래쪽에 있는 클러스터들은 나누어지고, 그 위쪽에 있는 클러스터는 병합된 것으로 간주됩니다.
덴드로그램 해석 방법: 1. 높이에 따라 클러스터 개수 결정 -> 덴드로그램에서 수평선을 자르는 높이를 기준으로 클러스터의 개수를 정할 수 있습니다. 예를 들어, 수평선을 높이 5에서 그으면 그 아래로 나눠진 클러스터 개수를 확인할 수 있습니다. 높이를 낮게 잡으면 많은 클러스터가 만들어지고, 높게 잡으면 적은 클러스터가 만들어집니다. 1.1높이가 낮은 부분에서 병합된 클러스터는 서로 유사성이 높습니다. 1.2 높이가 높은 부분에서 병합된 클러스터는 유사성이 상대적으로 낮습니다.
2. 병합 패턴 분석 -> 덴드로그램의 병합 패턴을 보면, 어떤 데이터들이 먼저 그룹화되고, 어떤 데이터들이 나중에 병합되었는지 알 수 있습니다. 비슷한 데이터를 초기에 클러스터링하고, 유사성이 적은 데이터를 나중에 큰 클러스터에서 병합하는 방식으로 데이터를 분석합니다.
3. 최적의 클러스터 선택 -> 최적의 클러스터 수를 선택하기 위해 덴드로그램의 가장 긴 수평선을 찾습니다. 이 수평선 아래로 분리된 클러스터가 서로의 거리가 크다는 뜻이므로, 그 지점을 기준으로 클러스터를 나누는 것이 일반적으로 좋습니다.
그럼 이제 사진을 보면서 설명하겠습니다.
사진에서 본 것과 같이, 병합 군집합은 밑에서부터(각 데이터 포인트가 개별 클러스터) 위로 서로 합쳐지면서 하나의 군집을 이루고, 분할 군집합은 위에서부터(가장 큰 하나의 군집합) 내려와 각각의 클러스터로 변하는 것으로 이해하면 편합니다.
그러면 이제 여기서 어떻게 클러스터의 갯수를 알 수 있을까요? 여기서는 병합 군집합만 설명하겠습니다. 먼저 밑에 숫자들이 있습니다. 관측치가 1과 3이 있습니다.
먼저, 1과 3에서부터 시작해 위로 올라가는 것을 수직선(Vertical Line - 위아래로 뻩어 있는 선)이라고 합니다. 그리고 갑자기 둘이 서로 이어져, 수평선(Horizontal Line - 좌우로 뻗어 있는 선)을 만듭니다. 참고로, 수직선과 수평선에는 의미가 있습니다. 수직선 - 수직선은 개별 데이터 포인트나 클러스터의 생성을 나타냅니다. 수평선 - 수평선은 클러스터 간의 유사성 또는 거리를 나타냅니다.(길이가 길면 = 서로 많이 다름, 길이가 짧으면 = 서로 유사하다 라는 뜻)
즉, 지금은 1과 3에 수직선이 있다는 것은 1의 클러스터, 3의 클러스터가 있다는 뜻이고, 서로 만났단는 것은 곧 병합이 되었고, 병합이 되어서 나온 수평선이 그들의 거리와 유사성을 의미한다는 것입니다.
이제 여기서 최적의 군집의 수를 구하는 것은 사실적으로 말하면 감 좋게 말하면 숫자를(1~10) 찍는것이라고 생각하면 됩니다. 편하게 숫자를 적고 코드를 적어 accuracy가 낮게 나오면 다른 값을 넣어서 최적의 값을 찾으면 된다는 뜻입니다(튜터님의 말씀!).
자, 그러면 강의에서 나온 코드를 실습을 하겠습니다. 밑에 그래프를 작업하는 부분만 구현하면 됩니다.
먼저, from sklearn.cluster import AgglomerativeClustering -> 이 코드를 통해 계층적 군집화를 쓸 수 있게 됩니다. 주요 매개변수: 1. n_clusters: 생성할 클러스터의 개수를 지정합니다.
2. affinity: 클러스터 간의 거리를 계산하는 방법을 설정합니다. 일반적으로 'euclidean' 거리 또는 'manhattan' 거리 등의 방법을 사용할 수 있습니다.
3. linkage: 클러스터를 결합할 때 사용할 방법을 지정합니다. (예: 'ward', 'complete', 'average', 'single')
import scipy.cluster.hierarchy as sch -> 이 모듈은 계층적 군집화에 대한 다양한 기능을 제공합니다. 계층적 군집화 기능: 1. linkage: 데이터를 계층적으로 연결하여 덴드로그램을 생성할 수 있습니다. 2. dendrogram: 덴드로그램을 시각화하여 클러스터의 구조를 쉽게 이해할 수 있습니다.
그럼이제 덴드로그램을 만드는 코드를 작성했습니다. plt.figure(figsize = (10,7)) dendrogram = sch.dendrogram(sch.linkage(data_scaler, method = 'ward')) plt.title('Dendrogram') plt.xlabel('Customers') plt.ylabel('Euclidean distances') plt.show()
보시는 바와 같이, 표가 만들어집니다. 여기서 최적의 군집의 수를 찾아야 하는데, 감으로 6으로 줘보겠습니다.
from sklearn.cluster import AgglomerativeClustering으로 불러온 병합 군집화를 사용할 수 있게 됩니다. 먼저, hc = AgglomerativeClustering(n_clusters=5, metric='euclidean', linkage='ward') 1. AgglomerativeClustering -> 계층적 군집화를 수행하기 위한 클래스입니다. 데이터 포인트를 점진적으로 클러스터로 합쳐가며 클러스터링을 수행합니다.
계층적 군집화: 계층적 군집화는 데이터 포인트를 계층적으로 클러스터링하는 방법으로, 두 가지 접근 방식이 있습니다: 상향식 (Agglomerative): 작은 군집에서 시작하여 큰 군집으로 결합합니다. 하향식 (Divisive): 큰 군집에서 시작하여 작은 군집으로 분할합니다.
2. n_clusters=6 -> 이 인자는 최종적으로 몇 개의 클러스터를 생성할지를 지정합니다. 여기서는 6개의 클러스터를 만들겠다는 의미입니다.
3. metric='euclidean' -> 클러스터 간의 거리를 측정하기 위한 방법을 설정합니다. 여기서는 유클리드 거리를 사용하고 있습니다. 유클리드 거리는 두 점 사이의 직선 거리를 의미하며, 기본적으로 2D 공간에서 두 점 간의 거리를 계산하는 방식입니다.
4. linkage='ward' -> 클러스터를 결합할 때의 방법을 정의합니다. 'ward' 방법은 워드 연결 방식으로, 클러스터 간의 분산을 최소화하는 방식입니다. 즉, 클러스터를 결합할 때, 결합한 후의 클러스터 내 분산이 최소가 되도록 합니다. 이 방법은 클러스터 크기가 비슷할 때 좋은 성능을 보입니다.
y_hc = hc.fit_predict(data_scaler) 이제 계층적 군집화를 학습을 시킴과 동시에 예측을 하게 만듭니다. plt.figure(figsize=(10, 7)) plt.scatter(data_scaler[y_hc == 0, 0], data_scaler[y_hc == 0, 1], s=100, c='red', label='Cluster 1') plt.scatter(data_scaler[y_hc == 1, 0], data_scaler[y_hc == 1, 1], s=100, c='blue', label='Cluster 2') plt.scatter(data_scaler[y_hc == 2, 0], data_scaler[y_hc == 2, 1], s=100, c='green', label='Cluster 3') plt.scatter(data_scaler[y_hc == 3, 0], data_scaler[y_hc == 3, 1], s=100, c='cyan', label='Cluster 4') plt.scatter(data_scaler[y_hc == 4, 0], data_scaler[y_hc == 4, 1], s=100, c='magenta', label='Cluster 5') plt.title('Clusters of customers') plt.xlabel('Age') plt.ylabel('Annual Income (k$)') plt.legend() plt.show() 이미 설명한 부분은 그냥 넘어가겠습니다. plt.scatter(data_scaler[y_hc == 0, 0], data_scaler[y_hc == 0, 1], s=100, c='red', label='Cluster 1'): plt.scatter는 산점도를 그리는 함수입니다. 잠깐, 여기서 산점도란? -> 산점도는 두 개의 변수 간의 관계를 시각적으로 나타내는 그래프입니다. 각 데이터 포인트는 두 변수의 값에 따라 x축과 y축에 위치합니다. 이를 통해 데이터의 분포, 패턴, 상관관계를 쉽게 이해할 수 있습니다.
data_scaler[y_hc == 0, 0]: 클러스터 1에 속하는 데이터 포인트의 x좌표를 가져옵니다. 여기서 data_scaler는 정규화된 데이터 세트를 의미하고, y_hc == 0는 클러스터 1에 속하는 인덱스를 가져옵니다.
data_scaler[y_hc == 0, 1]: 클러스터 1에 속하는 데이터 포인트의 y좌표를 가져옵니다.
s=100: 각 데이터 포인트의 크기를 설정합니다. 여기서는 100으로 설정하여 포인트가 큽니다.
c='red': 클러스터 1의 색상을 빨간색으로 지정합니다.
label='Cluster 1': 범례에 사용할 라벨을 설정합니다. 여기서 범례란? -> 범례(legend)는 그래프나 차트에서 각 데이터 시리즈나 데이터 포인트의 의미를 설명하는 텍스트 박스입니다.
다른 plt.scatter 호출: 나머지 plt.scatter 호출도 비슷한 방식으로 작동합니다. 각 클러스터(2, 3, 4, 5)에 대해 각각 다른 색상과 라벨을 지정하고 있습니다. 예를 들어: y_hc == 1인 경우(클러스터 2)는 파란색, y_hc == 2인 경우(클러스터 3)는 초록색, y_hc == 3인 경우(클러스터 4)는 청록색, y_hc == 4인 경우(클러스터 5)는 마젠타색으로 설정되어 있습니다.