회귀 머신은 연속적인 값을 예측하는 데에 쓰이는 해결 방법이자 하나의 알고리즘입니다. 여러가지가 있지만 가장 기초적인 부분은 바로 선형 회귀입니다. 주어진 입력 데이터로부터 출력 값을 예측하고, 그 관계를 직선으로 모델하는 것이 바로 선형 회귀 입니다.
그 전에 먼저, 머닝 러신의 기초에 대해 알아봅시다.
머닝 러닝에서는 정말 수 많은 학습 방법이 있으며, 이 학습들을 기반으로 AI는 다양하게 학습할 수 있습니다.
1. 지도 학습 -> 규칙과 정답을 통해 인공지능이 학습을 하여, 다른 결과물도 출력하게 하는 것입니다.
2. 회귀 -> 연속적인 값에서 규칙을 학습하는 문제
3. 비지도 학습 -> 정답이 없지만 비슷한 데이터들을 찾아 학습하는 것입니다.
4. 강화 학습 -> 순차적 학습(순차적으로 실제로 영향을 주는 것)입니다.
5. 앙상블 학습 -> 여러개의 모델을 결합하여 더 좋은 성능을 얻는 방법입니다.
따로 설명을 하자면, 지도 학습은 정답을 찾기 위해, 비지도 학습은 분류를 위해(비슷한 데이터를 카테고리화), 강화 학습은 자신이 행동을 하기위한 근거를(나뭇가지을 쓴다고 하면 왜 나뭇가을 써야하는지) 사용합니다.
| 머신 러닝의 구성 요소 |
| 1. 데이터 셋 -> AI에게 학습을 시키기 위해 데이터는 무조건 필요합니다. |
| 2. Feature(특징) -> 어떠한 입력(값)을 가지고 있는지에 대한 조건입니다. (데이터 규칙 확인) |
| 3. 레이블 -> 실제로 데이터의 규칙과 데이터를 전달하고, 자신이 따로 기대하는 값이라고(출력) 생각하시면 편합니다. |
| 4. 모델 -> 실제로 코드를 만들어 AI가 특징과 정답을 예측할 수 있게 도와주는 것을 말합니다. |
| 5. 학습 -> 학습을 완료하고, 다른 데이터를 추출해 낼 수 있는지에 대한 역량을 확인하는 것. |
회귀 머신
먼저 회귀 머신의 수식은 다음과 같습니다.
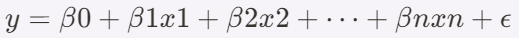
먼저,
y: 예측하려는 종속 변수(목표 값)입니다. 즉, 우리가 알고 싶은 값이에요.
β0 (베타 0): 절편을 의미합니다. 독립 변수들이 0일 때, y 값이 어떤지를 나타냅니다.
β1, β2, ..., βn (베타 1, 베타 2, ..., 베타 n): 회귀 계수입니다. 각 독립 변수(x1, x2, ..., xn)에 대한 가중치입니다. 즉, 각 변수들이 예측 값(y)에 얼마나 영향을 미치는지를 나타냅니다.
x1, x2, ..., xn: 독립 변수들입니다. 이 변수들은 우리가 예측에 사용하는 데이터입니다. 여러 개의 독립 변수가 있을 때는 다중 회귀 분석을 합니다.
ε (epsilon): 오차 항입니다. 모델이 실제 값과 예측 값 사이에 발생하는 차이를 나타내며, 우리가 설명하지 못하는 부분이 포함된 값입니다.
이것을 그래프로 한다면,
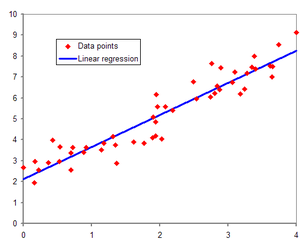
즉, 선형 회귀는 데이터가 완벽하게 직선을 따르지 않더라도, 전체적인 경향을 파악해서 데이터를 설명하는 최적의 직선을 찾는 방법입니다.
여기서 가중치에 대해 배워봅시다.
예시를 들어봅시다.
만약,
a = 1,2,3,4,5
b = 15,20,25,30,35
이렇게 규칙이 있습니다. a가 1씩 올라갈 때마다, b는 5씩 증가하는 상황입니다. 따라서 기울기는(𝛽1)는 5입니다. (증가하는 값)
그리고, 만약에 a = 0일때의 b의 값을 예상을 해 봤을때, b는 10이라고 예측할 수 있습니다. 그렇기에 절편(즉,𝛽0)은 10입니다.
따라서 위에 대한 수식을 제대로 이해하고, 수식을 따라 만든다면, b(y) = 10 + 5(𝛽1)a(x)입니다.
참고로 b를 통해 a를 만들 수 있습니다. 위에 식 그대로 반대로 돌리면 됩니다.
그렇게 하면,
b = 15일때, a = 15 - 10 / 5 = 1
b = 20일때, a = 20 - 10 / 5 = 2가 되므로 둘 다 구할 수 있습니다.
팁!
𝛽₁는 기울기(slope)로, 독립 변수 x가 1만큼 증가할 때 종속 변수 y가 얼마나 변하는지를 나타냅니다.
𝛽₀는 절편(intercept)으로, x=0일 때 y의 값을 의미합니다.
만약에 c = 30, 35, 40, 45, 50이 추가가 된다면 어떻게 될까요?
바로
a=𝛽0+𝛽1b+𝛽2c 이렇게 됩니다. 그런데 약간 복잡합니다
이번에는 코드를 써보겠습니다.
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# 데이터 준비
a = np.array([1, 2, 3, 4, 5])
b = np.array([15, 20, 25, 30, 35])
c = np.array([30, 35, 40, 45, 50])
# 데이터프레임 생성
data = pd.DataFrame({'a': a, 'b': b, 'c': c})
# X (독립 변수)와 y (종속 변수) 설정
X = data[['b', 'c']]
y = data['a']
# 선형 회귀 모델 생성 및 학습
model = LinearRegression()
model.fit(X, y)
# 회귀 계수
beta_0 = model.intercept_
beta_1, beta_2 = model.coef_
print(f"회귀 방정식: a = {beta_0} + {beta_1} * b + {beta_2} * c")일단 array를 통해 값들을 전부 넣어주었고,
데이터를 구조적으로 다루고 다양한 분석 기능을 활용할 수 있는 Pandas의 데이터 프레임으로 만들었습니다.
그리고 독립 변수와 종속 변수를 설정을 하고, LinearRegression을 통해 선형 회귀를 수행합니다.
그리고 fit()을 통해 학습을 시키면서, .intercept, coef를 통해 절편과, 기울기를 계산해, 추출해 냅니다.
자, 여기서 하나 알아가야할 중요한 개념이 있습니다. 바로 beta_1, beta_2 = model.coef_ 처럼, 한번에 변수 두개를 줘도 되는걸까요? 이것은 바로 튜플 언팩킹이라는 개념이 있습니다. 파이썬에서 지원하는 기능이며, 여러 값을 여러 변수에 쉽게 할당할 수 있게 해줍니다. 즉, 독립 변수를 2개를 선언했으니, 2개를 받아야 하는 상황이므로, 만약 2개를 줬는데, 3개를 받을려고 하면 오류가 뜹니다.
그리고 아까 가중치라는 개념이 나왔는데, 가중치는 위에서 나온 기울기들이라 생각하시면 됩니다. 자, 여기서 목적 함수라는 개념도 나옵니다. 가중치를 통해 값을 전달하고, 내가 예상한 값과 가중치를 통해 계산된 값의 차이를 나타내는 수치를 목적 함수라고 합니다. 그리고 제일 중요한 점은, AI는 실제로 규칙을 찾아내는 것도 있지만, 목적 함수를 최소화 한 값을 찾아내는 것을 학습이라고 합니다. (β1, β2....의 계산에서 오차를 최소한으로 내는것을 말합니다)
+
기울기가 하나만 존재하여 규칙이 쉬운 것을 단순 선형 회귀라고 하고
기울기가 여러개 존재하여 불규칙처럼 보이는 것을 다중 선형 회구라고 합니다.
중요 포인트
fit() -> 이 메서드는 주어진 입력 데이터(독립 변수)와 출력 데이터(종속 변수)를 사용하여 모델을 학습합니다.
model. -> LinearRegression() 클래스를 통해 생성됩니다. 이 클래스는 선형 회귀 모델을 구현하는 데 사용됩니다.
.intercept -> 이것은 큰 의미가 있는 것이 아니라, 절편(β0)의 값을 구해주는 역할을 합니다.
.coef -> 이것도 마찬가지로 회귀 계수, 또는 기울기를 구해주는 역할을 합니다.
알아야할 model.의 다양한 속성과 메서드들.
| model.intercept_ : 회귀 직선의 절편을 반환합니다. 이는 종속 변수의 예상값이 독립 변수가 0일 때의 값입니다. model.coef_ : 각 독립 변수에 대한 회귀 계수를 반환합니다. 이는 독립 변수가 종속 변수에 미치는 영향을 나타냅니다. model.fit(X, y) : 주어진 독립 변수 X와 종속 변수 y에 대해 모델을 학습시킵니다. model.predict(X_new) : 새로운 독립 변수 X_new에 대해 종속 변수를 예측합니다. model.score(X_test, y_test) : 주어진 테스트 데이터에 대한 R² 점수를 반환합니다. R² 점수는 모델이 데이터를 얼마나 잘 설명하는지를 나타냅니다. model.get_params() : 모델의 하이퍼파라미터를 딕셔너리 형식으로 반환합니다. 예를 들어, fit_intercept와 normalize와 같은 파라미터를 포함합니다. model.set_params(**params) : 모델의 하이퍼파라미터를 설정합니다. 예를 들어, 특정 파라미터의 값을 변경할 때 사용됩니다. model.n_features_in_ : 모델에 사용된 독립 변수의 수를 반환합니다. 이 값은 모델이 학습한 입력 특성의 수를 나타냅니다. model.n_iter_ : 모델이 수렴하는 데 필요한 반복 횟수를 반환합니다. 다만, 이 속성은 LinearRegression에서는 항상 1이 됩니다. |
그럼 이제, 강의에 나온 코드들을 한번 분석하겠습니다.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 데이터 생성
X = np.array([[1, 1], [2, 2], [3, 3], [4, 4], [5, 5],[6,6]])
y = np.array([1, 2, 3, 4, 5, 6])
# 데이터 분할 (훈련 데이터와 테스트 데이터)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 선형 회귀 모델 생성 및 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 모델 평가
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
print(f'R^2 Score: {r2}')한 줄, 한 줄 보겠습니다. 먼저
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
sklearn.model_selection -> 데이터셋을 훈련 세트와 테스트 세트로 나누는 기능, 교차 검증, 하이퍼파라미터 튜닝 등을 제공합니다.
여기서, model_selection: 모델 선택 및 평가와 관련된 기능을 제공하는 모듈입니다.
train_test_split: 데이터를 훈련 세트와 테스트 세트로 나누는 함수입니다. 일반적으로 모델의 성능을 평가하기 위해 사용됩니다.
sklearn.linear_model -> 선형 회귀, 리지 회귀, 라쏘 회귀 등을 포함합니다.
여기서, linear_model: 선형 회귀와 관련된 알고리즘을 구현한 모듈입니다.
LinearRegression: 기본적인 선형 회귀 모델을 구현한 클래스입니다. 데이터에 대한 회귀 분석을 수행합니다.
sklearn.metrics -> 회귀 모델 평가를 위한 MSE(평균 제곱 오차), R² 점수, 분류 모델 평가를 위한 정확도, 정밀도 등을 포함합니다.
여기서, metrics: 모델의 성능을 평가하는 데 사용되는 다양한 메트릭과 함수를 제공하는 모듈입니다.
mean_squared_error: 예측값과 실제값 간의 평균 제곱 오차를 계산하는 함수입니다. 모델의 예측 성능을 측정하는 데 사용됩니다.
r2_score: 모델의 설명력을 나타내는 R² 점수를 계산하는 함수입니다. 1에 가까울수록 모델이 데이터를 잘 설명하고 있다는 의미입니다.
잠깐! 여기서 R²란? -> R² 값은 0에서 1 사이의 값을 가집니다.
R² = 1: 모델이 데이터를 완벽하게 설명합니다. 즉, 모든 데이터 포인트가 모델의 예측 값과 일치합니다.
R² = 0: 모델이 데이터의 변동성을 전혀 설명하지 못합니다. 이 경우, 모델은 평균값으로 예측하는 것과 동일합니다. 0 < R² < 1: 모델이 데이터의 변동성 중 일부를 설명합니다. 값이 클수록 모델이 데이터를 잘 설명하고 있다는 의미입니다.
X = np.array([[1, 1], [2, 2], [3, 3], [4, 4], [5, 5],[6,6]])
y = np.array([1, 2, 3, 4, 5, 6])
기본적으로 독립 변수와, 종속 변수를 선언했습니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
여기서 train_test_split을 사용하면 데이터를 나누는데, 저 X는 입력 데이터, y는 목표 변수, test_size = 0.2는 데이터의 20%를 테스트 세트로 사용한다는 뜻이고, 80% 훈련 세트로 사용한다는 뜻입니다.(참고로 훈련 세트는 70%~90%가 일반적입니다.). 여기서 random_state는 방금과 말했다 싶이, 20%는 테스트, 80%는 훈련에서 20%로 쓰일 데이터가 무작위로 쓰이는 데, random_state가 그것을 방지하고, 직접 선택할 수 있게 해줍니다. 숫자가 42인 경우는 아직 이해하기 어려우니 지금은 스킵...(난수 생성 알고리즘)
여기서 문제, 근데 왜 받는 변수가 4개일까? 바로 20%의 X와 y가, 80% X와 y가 있어, 4개를 받는것!
model = LinearRegression()
model.fit(X_train, y_train)
이 부분을 통해 선형 회귀 모델을 소환하고, fit을 통해 학습을 시킨 다음,
y_pred = model.predict(X_test)
.predict를 통해 확인을 합니다.
자, 이제 MSE에 대해 알아보겠습니다 R2에 대해 알아보겠습니다.(R2의 설명은 이미 끝..이지만 그래도 다시!)
MSE -> 평균 제곱 오차(Mean Squared Error)는 모델이 예측한 값과 실제 값 간의 차이를 제곱하여 평균한 것입니다.
MSE는 값이 작으면 작을수록 모델의 예측이 실제 값에 더 가까움을 의미하고, R2또한 마찬가지로 1에 가까울수록 모델이 잘 설명하고 있다는 것을 의미합니다.
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
그렇기에 이 두개를 사용해 차이와, 평가를 하는 것 입니다.
이제부터 나올 회귀는 전부 회귀모델 중 하나 입니다.
다항 회귀
기본 술식은 다음과 같습니다.

다항 회귀, 리지 회귀, 라쏘 회귀는 선형 회귀의 변형된 형태입니다. 결국 다른점은 독립 변수의 차수를 증가시켜 비선형 관계를 반영합니다.
하지만 다항 회귀는 데이터가 곡선 형태로 분포하는 경우에 적합하지만, 차수가 높을수록 모델이 더 복잡해지며, 에러(과적합)의 위험이 있습니다.
리지 회귀
기본 술식은 다음과 같습니다.

리지 회귀는 정규화(regularization) 기법을 사용하는 선형 회귀 모델입니다. 모델의 가중치(회귀 계수)가 너무 크지 않도록 제약을 부과하여 과적합(overfitting)을 방지하는 것이 목표입니다. 특히 다중 공선성 (독립 변수들 간의 상관관계)이 존재하는 데이터셋에서 효과적입니다.
목적 함수 : 리지 회귀는 선형 회귀의 비용 함수에 가중치의 크기를 제한하는 항을 추가합니다. 리지 회귀의 비용 함수는 다음과 같습니다:
기본 술식은 다음과 같습니다.
라쏘 회귀

리지 회귀와 달리, 라쏘 회귀는 일부 변수의 가중치를 완전히 0으로 만들 수 있습니다. 즉, 불필요한 변수를 선택적으로 제거하는 특성 선택 기능이 있습니다.
라쏘 회귀는 필요 없는 변수를 모델에서 제거할 수 있습니다. 이로 인해 변수 선택이 중요한 문제(예: 고차원의 데이터)에서 효과적입니다. 이는 리지 회귀와의 주요 차이점입니다.
로지스틸 회귀
로지스틱 회귀는 입력 변수와 결과 변수 간의 관계를 모델리하는 데 유용하며, 결과 변수는 두 가지 클래스 중 하나(예: 0 또는 1, 합격 또는 불합격)로 나타납니다. 그렇기에 시그모이드 함수를 사용합니다. 참고로 분류 작업에 사용됩니다.
그리고 여기서 선형 회귀와의 차이가 분명히 나타납니다.
선형 회귀: 입력 변수의 가중치 합을 통해 연속적인 값을 예측합니다. 결과는 무한한 범위를 가질 수 있습니다.
로지스틱 회귀: 선형 회귀에서 생성된 예측 값을 0과 1 사이의 확률로 변환하여 이진 분류 문제에 적합하게 만듭니다.

여기서 z는 입력 변수와 그 가중치의 선형 조합입니다.

오늘은 여기까지...