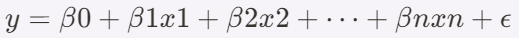계속 이어가겠습니다.1. ptimizer.zero_grad()기울기(gradient)를 0으로 초기화하는 단계입니다. 역전파(backward)를 실행할 때 그레디언트가 계속해서 누적되므로, 매번 새로운 학습 단계에서 기존의 그레디언트를 초기화해야 합니다. optimizer.zero_grad()는 이전 배치에서 계산된 그레디언트를 지워주는 역할을 합니다. 만약 이 작업을 하지 않으면, 이전 배치의 기울기가 이번 배치에 누적되어 잘못된 업데이트가 이루어질 수 있습니다.2. outputs = model(inputs)입력 데이터를 모델에 넣어 예측 값을 얻는 단계입니다. model(inputs)는 모델이 입력 데이터를 받아 순전파(forward pass)를 통해 예측값(outputs)을 생성하는 과정입니다. 여..