Outlier -> data that is out of the normal data value
How to deal with it?
1. describe -> check the normal data
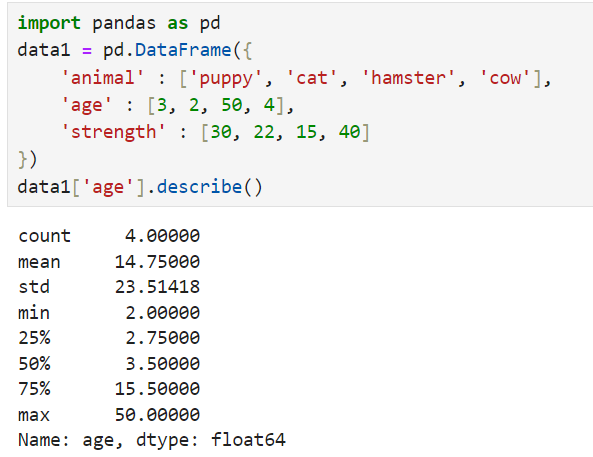
From here, if the gap between the mean and std and max is abnormally high, that means there is an outlier
I can also use box plot and histogram to check if there is an outlier
but, before that must bring matplotlib.pylplot as plt

Or maybe, I can use IQR(Interquartile Range) -> IQR is the difference between the 1st quartile (Q1) and the 3rd quartile (Q3), and data outside this range can be considered outliers.
Normalization is the process of converting the range of data to between 0 and 1.
Before that, I must know what data preprocessing -> Data preprocessing refers to the process of converting data into data suitable for modeling or analysis. Data may originally be incomplete or contain errors, making it difficult to use immediately. Therefore, various tasks are required to organize and convert the data. This process is called data preprocessing.
1. Min-Max Normalization.

Min-Max normalization is a method of transforming data into a range between a minimum value of 0 and a maximum value of 1.
2. Z-score normalization(Standardization) -> Z-score normalization is a way to express how far each data point is from the mean, based on standard deviations.

The values of the data are converted to standard deviation units from the mean.
Nonlinear Transformation - Nonlinear transformation is used to make the non-normal distribution of data closer to a normal distribution. ->
1. Log
2. Square Root
3. Box-Cox
1. Log ->Log transformation is mainly used for positive data and is useful for narrowing the distribution of data. It is especially effective when dealing with data with an exponential distribution. When the original values show a large difference, processing this data with a log transformation reduces the values that appear too large and makes them look like they are of similar size.
The exponential distribution is one of the probability distributions, and is mainly used to model the time it takes for an event to occur after the next event.

2. Square Root -> The square root transformation is another way to flatten the distribution of data, especially data with a Poisson distribution.
Before that, what is poisson distribution? -> describes the probability that an unpredictable event will occur. It mainly describes the number of times an event occurs. = same as uncountable data or unexpectable data

3. Box-Cos -> Box-Cox transformation** is a nonlinear transformation method used to make the distribution of data closer to a normal distribution. However, this transformation can only be used on positive data. This is because it uses a similar principle to the log transformation.
Positive data refers to data that has a value greater than 0.


Encoding -> Encoding is the process of converting data into a specific format. In particular, converting categorical data into numerical data is an important encoding task in machine learning.
1. Label Encoding - Label encoding converts categorical data into ordered numbers, where each category is assigned a unique number. For example, if we label - encode the gender variable, male would be converted to 0 and female would be converted to 1. All unique categorical values would be converted to integers, and the converted values would not imply any order of magnitude.

2. One - hot encoding - is a method of converting each categorical value into a binary vector. It is converted into a vector of 0s and 1s depending on the number of categories. For example, if a variable called color has three categories: red, blue, and green, each would be converted as follows:
Red: [1, 0, 0]
Blue: [0, 1, 0]
Green: [0, 0, 1]

3. Ordinal encoding - is used when there is an order to categorical data. For example, when the education level is listed as high school graduate, college graduate, master's degree, and doctorate, it is a method of converting each value to 0, 1, 2, and 3 according to the order.

Good night