Well, I was able to learn what Python is. and its basic information. There was more and more information
Especially, the class part made me hard all the time. I even thought 'Wasn't class the same as the function?' well, that was wrong. I was able to know that class is like a huge mechanism for the whole body. I was even mad about class. because it was hard enough to make me mad. but it was nothing compared to the other information I will study. I'm sure I will do better next time. well, not only next time but always.
Well, I was able to learn a lot this weekend. starting from Python to Numpy and Pandas in this weekend.
Starting with the basics of Python. Variables, functions(print(), len(), def, etc...), class, Dataframe, Series.
Starting with variables and to the end. I will show you what I studied.
1. box of the data (int, float, str, bool, list, tuple, dict, set)
2. list -> []
3. dictionary -> {}
4. tuple -> () -> can not be changed
5. set -> {}
6. operator -> =, ==, +, -, <, >, <=, >=, **, *, //, %, /, etc
7. if -> elif, else
8. for -> while
9. function -> print(), sort(), def etc
10. Class -> __init__, __iter__, __next__, __add__ etc
11. Object-oriented -> parameter, argument
12. exception -> try, except, finally, raise
13. module and package -> import and pip
14. reading -> open(), with, write() etc.
That was hard!
For Numpy and Pandas
Numpy -> more on calculation -> series
Pandas -> more on database -> DataFrame
np.subtract() -> same as '-'
Well, this is a TIL for today(I mixed it....^^)

np.multiply() -> same as '*'
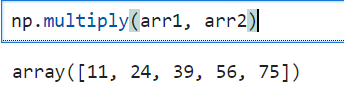
np.floor_divide() -> same as '/' but, it will give in int type(not in float type)
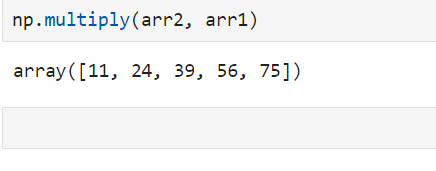
np.mod() -> same as %(will only get remains)

** -> exponent

np.median() -> will get the middle value(if there is no middle, it add the two middle value and get the average)
np.std() -> will get standard deviation
np.argmin(max)() -> will get the location of the minimum number
np.ptp() -> shows the gap between the minimum and maximum value
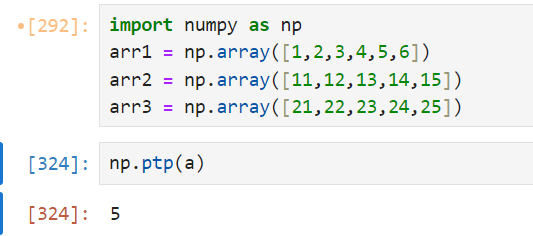
6(maximum) - 1(minimum) = 5
Now I have to talk about the pandas.
Then what is pandas? first, I have to know that
numpy -> suitable for calculation
pandas -> suitable for data analysis
So, they do have different codes
2 concepts I must know
1. series -> 1st dimension data frame. It is similar to a column or list in Excel.
2. DataFrame -> 2nd dimension data frame. It is similar to a table in Excel and contains data organized into rows and columns.
Basic frame
1. Series -> first dimension frame, similar to the list
import pandas as pd
# 리스트로 시리즈 만들기
s = pd.Series([1, 3, 5, 7, 9])
result:
print(s)
0 1
1 3
2 5
3 7
4 9
dtype: int64
here, the left numbers are called 'index' and the right numbers are real data.
So, we can also set the index too
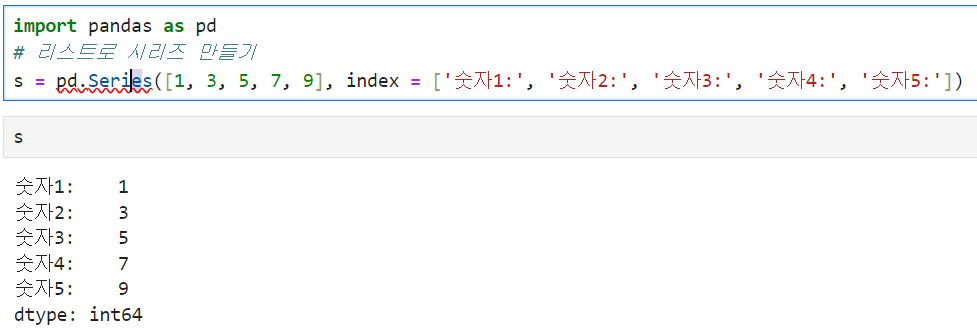
Like this.
2. DataFrame - 2nd dimension, dictionary form
import pandas as pd
# 딕셔너리로 데이터프레임 만들기
data = {
'이름': ['홍길동', '이순신', '강감찬'],
'나이': [20, 40, 30],
'성별': ['남', '남', '남']
}
df = pd.DataFrame(data)
print(df)
result:
이름 나이 성별
0 홍길동 20 남
1 이순신 40 남
2 강감찬 30 남
3. CSV - Comma-Separated Values, used when exchanging the data
Ex, of CSV file
이름,나이,직업
홍길동,30,프로그래머
김철수,25,디자이너
이영희,35,데이터 분석가
How to get the CSV file?
df = pd.read_csv('파일경로/파일이름.csv')
print(df)
Then some codes can be used to read it.
1. df.head(): Check the top 5 data (preview only the first few lines) (I can set the number of the data ex.data(7) -> 7 datas will be shown
2. df.tail(): Check the bottom 5 data
3. df.info(): Output information such as the structure of the data frame, data type, and memory usage
4. df.describe(): Summarizes basic statistical information for numeric data
4. Choosing column
print(df['이름'])
result:
0 홍길동
1 이순신
2 강감찬
Name: 이름, dtype: object
5. Adding data
df['주소'] = ['서울', '부산', '대구']
print(df)
result:
이름 나이 성별 주소
0 홍길동 20 남 서울
1 이순신 40 남 부산
2 강감찬 30 남 대구
6. filtering the data
df_filtered = df[df['나이'] > 25]
print(df_filtered)
result:
이름 나이 성별 주소
1 이순신 40 남 부산
2 강감찬 30 남 대구
7. sort by
df_sorted = df.sort_values(by='나이')
print(df_sorted)
This code sorts ascending by age.
important option
1. sep -> Specify a delimiter, the default is ','
Delimiter: Indicates the criteria by which columns are separated.
2. header -> Specifies the header row. The default is the first row (0).
Also,
I could also get CSV files from the internet
url = '<https://example.com/data.csv>'
df_csv_url = pd.read_csv(url)
print(df_csv_url.head())
Bringing excel file -> read_excel
ex.
dex = pd.read_excel('code.xlsx')
print(df_excel)
Bringing JSON file -> read_json
djs = pd.read_json('ulti.json')
print(df_json)
But, what is json?
JSON (JavaScript Object Notation) is a lightweight data format for storing and transmitting data. It is mainly used in web applications to exchange data between servers and clients.
1. JSON Structure
JSON consists of two main data structures:
Object: A set of key-value pairs surrounded by {}
Array: A list of values surrounded by []
ex.
{
"이름": "홍길동",
"나이": 25,
"취미": ["독서", "등산", "요리"],
"주소": {
"도시": "서울",
"우편번호": "12345"
}
}
saving data into CSV file
Ex.
import pandas as pd
df_info = pd.DataFrame ({
'name' : ['kevin', 'Mina', 'Nikka'],
'height' : [174, 164, 158],
'wight' : [76, 54, 45]
})
df_info.to_csv('data.csv', index=False)
file name.to_csv('name of data to save', index = False) -> index = false means it will save without index
The Excel and json have the same frame to save as the CSV
orient: Specifies the JSON format. The default is columns. You can save in various formats such as records, index, etc.
But
saving to SQL database must use to_sql, and must connect to the database
import sqlite3
# Connect to SQLite database
conn = sqlite3.connect('database.db')
# Save the dataframe as an SQL table
df.to_sql('table_name', conn, if_exists='replace', index=False)
# Close connection
conn.close()
- `name`: Specifies the table name to save.
- `con`: Specifies the database connection object.
- `if_exists`: Specifies the action if the table already exists. Choose from `replace`, `append`, and `fail`.
- `index=False`: Saves without index.
checking the called data
As I mentioned earlier
1. df.head(): Check the top 5 data (preview only the first few lines) (I can set the number of the data ex.data(7) -> 7 datas will be shown
2. df.tail(): Check the bottom 5 data
3. df.info(): Output information such as the structure of the data frame, data type, and memory usage
4. df.describe(): Summarizes basic statistical information for numeric data
1. .head()
2. .tail()
3. .info()
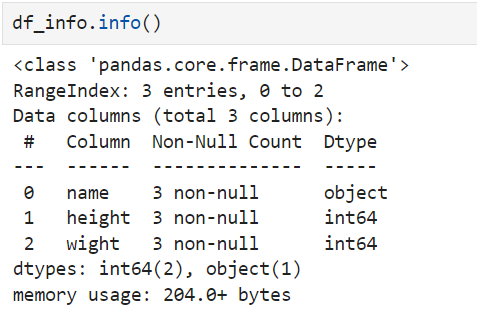
non-Null coount -> shows the number of the non-null(exist data) 3 non-null -> meaning there are 3 exist data
4. .sample() -> will get the random data ()- > number of the data
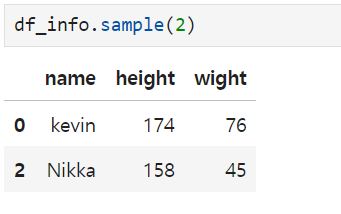
5. .describe()
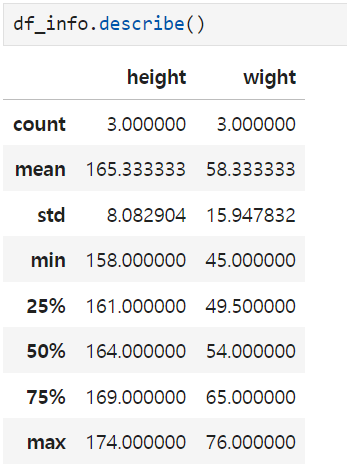
6. .dtypes -> show the all types of the data
7. .columns -> show all columns in the data(also can use index)

But what if I try to see specific data? ->
name of the data['name of the column].describe()
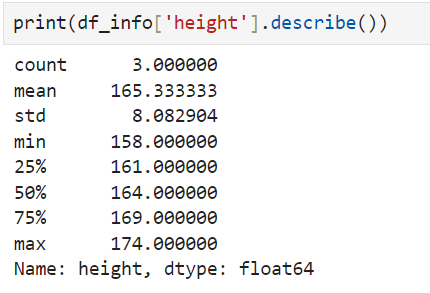
8. loc[] -> to see the individual data(column and row)
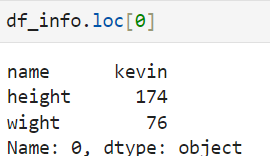
or
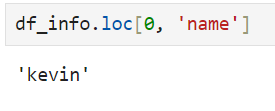
or
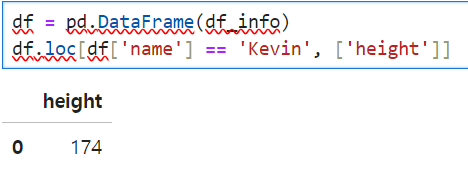
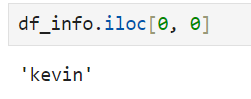
9. iloc[] -> use int index. ex. df_info.loc[0. 'name'] = df_info.iloc[0, 0]
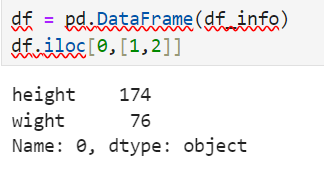
Also I can call a row(write in list type, one more '[]')
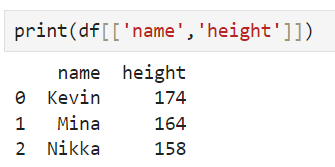
DataFrame.loc[row, column]
DataFrame.iloc[row, column]
But should not use [] if I'm going to use index slicing (ex. 0:2 o, [0,2] x)
Tip! -> inplace - used when saving the changed value (data frame to be changed).
inplace = False (do not save)
inplace = True (save)
drop -> When choosing the column to use as an index, it will decide whether to include the index or not
drop = True -> Do not include column
drop = False -> include column
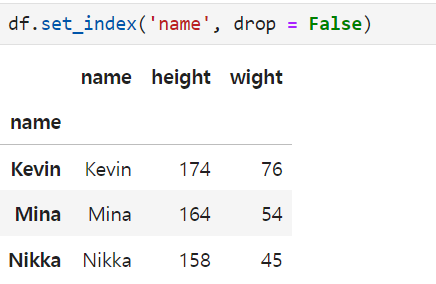
From here, the name option has been added again because of the drop
+When choosing rows, I cannot use like df[0], because it has to be in slicing form, like df[0.2]
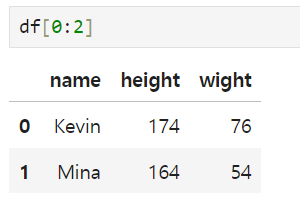
Selecting data
index
1. set_index()
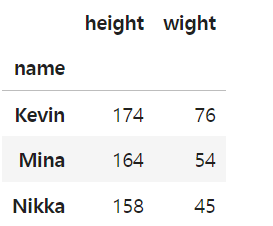
As I can see, the main index is now 'name'
Filtering -> giving a condition and if the condition is satisfied, it will be shown
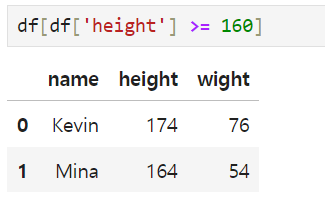
can also use 'and(&)' and 'or(|)'

And remember that If there are multiple conditions, I have to use () on each condition, and I cannot use the word 'and' and 'or'. I have to use & and | instead

.loc[:,'name'], since I can't give the name of the column, I gave a whole slicing(;)
.isin() -> isin() returns True if the values of a specific column are within the range.
ex.
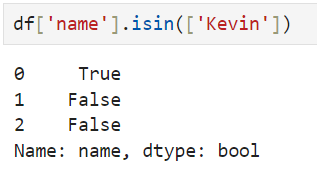
Remember not only (), but also gave []
~ -> same as 'not'
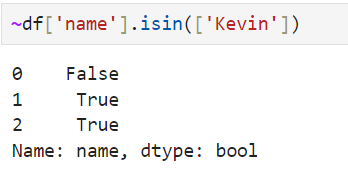
True -> False
False -> True
Additionally, If I cover that whole code by []

It will show in the table form.
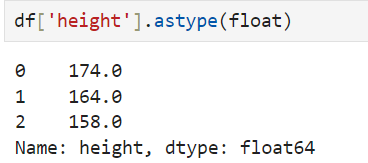
1. Changing data type
.astype() -> will change the data type
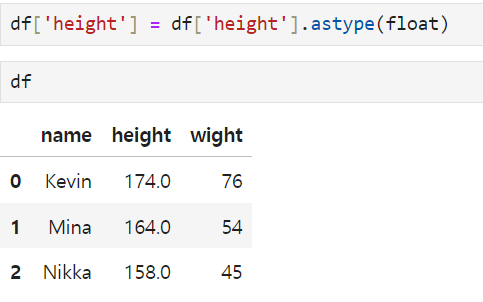
How to save the data?
How to deal with missing data? ->
.fillna() -> replaces missing values with appropriate values.
2. date type -> pd.to.datetime() - will change the data type into date type
3. category type -> .astype('category')
arraying the data
1. sort_values()
2. sort_index()
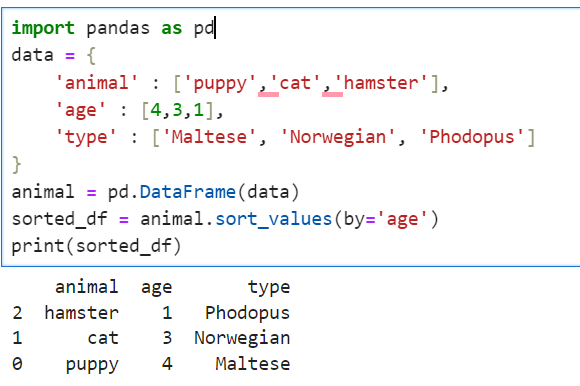
.sort_value(by = 'standard')
and look at this
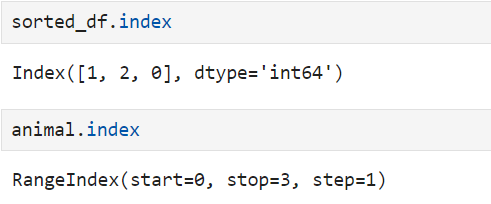
It has a different index type. The sorting operation does not change the index in any way. That is why the rangeindex is output, but you can see that the index is just output by touching the index sorting due to the sorting operation.
and for descending -> ascending = False
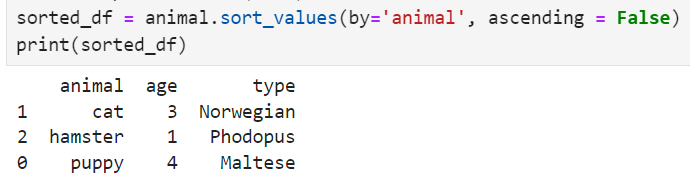
Can also give multiple standards as well as the ascending type(useful if there are duplicated values)
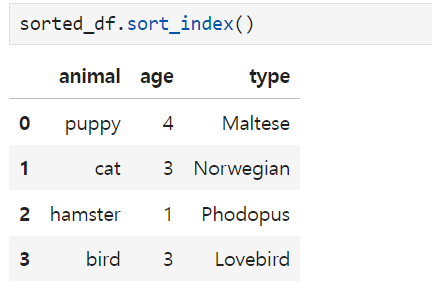
2. sort_index() -> will array based on the index number (can also use ascending = False or True inside of ())
Merging the data
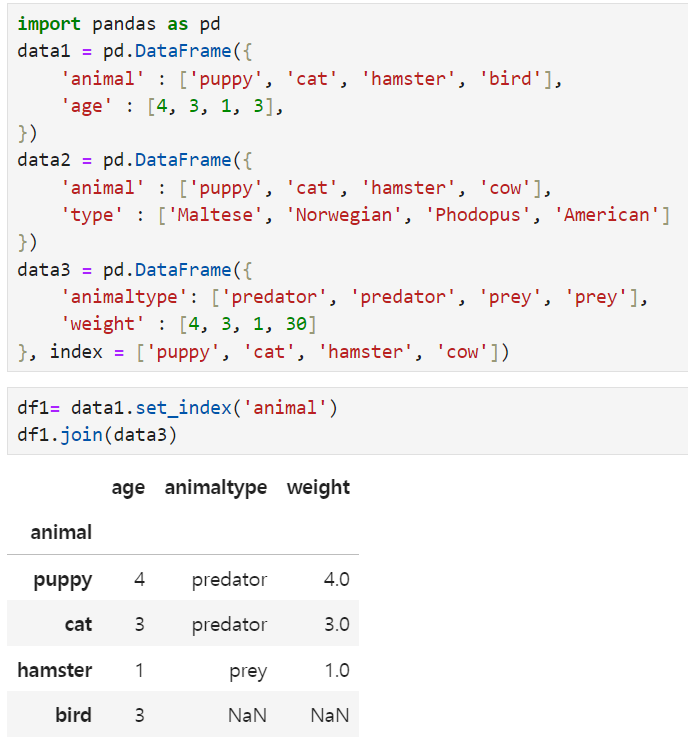
merge() - When there are two data frames, if there is a common column, the data is merged based on that common column.
Remember. It's adding all the data. but only gets the duplicated values in a certain column
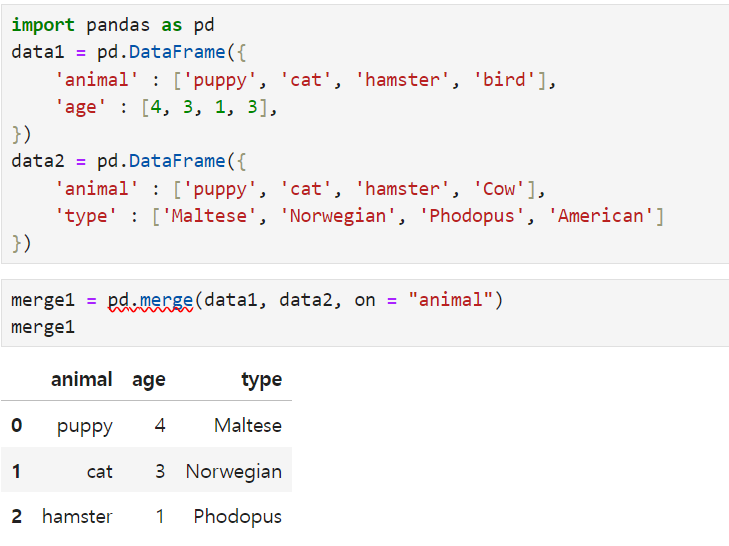
the Bird, and Cow have been deleted because they are not the same. but the other values(puppy, cat, hamster) are shown. then I can use how 'instead' of 'on' ex. how = left or right or outer(left - will remain the left data(data1), right - will remain the right (data2) outer - all of the data will be merged)
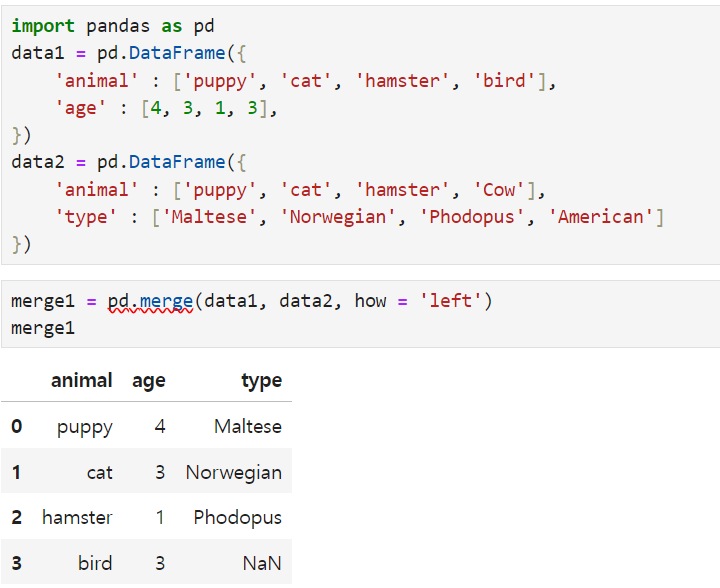
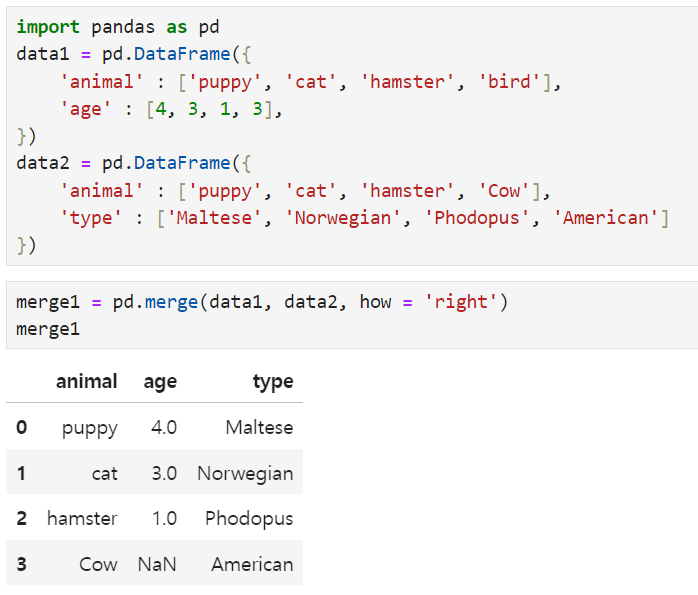
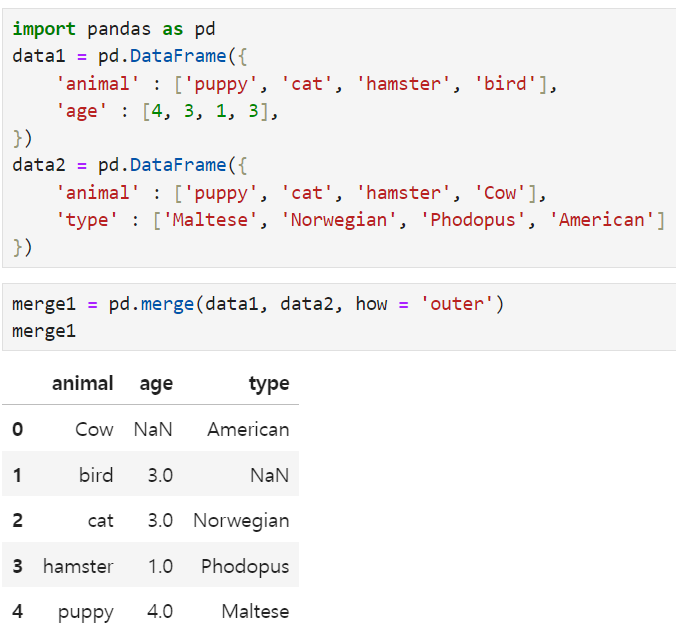
Additionally, NaN -> if there is no duplicated data, it will be NaN
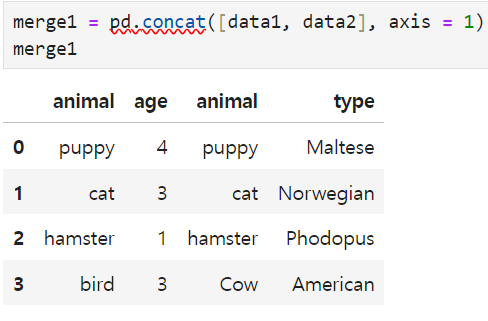
concat() - merge all the part
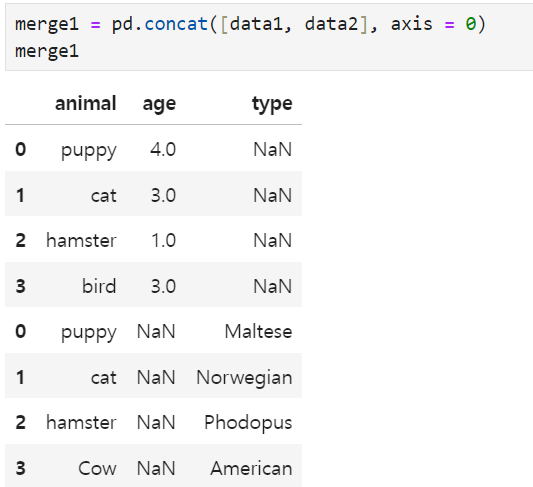
since data1 has no 'type' value, it will have NaN
If I put 1 in the axis, it will be merged by column, and if you put 0, it will be merged by row.
join() -> can merge based on index.
Grouping and Aggregation, PivotTables
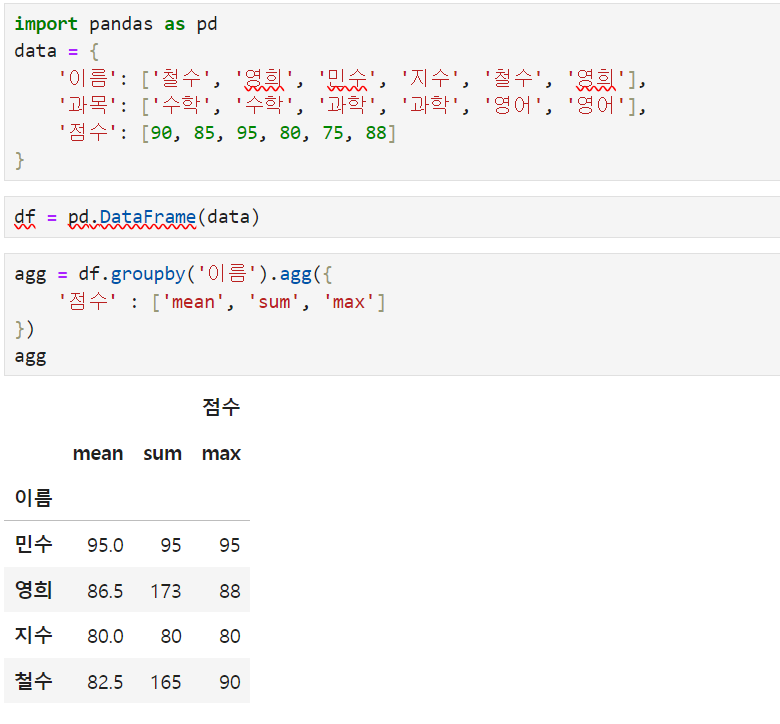
1. groupby() -> groups data based on a specific column.
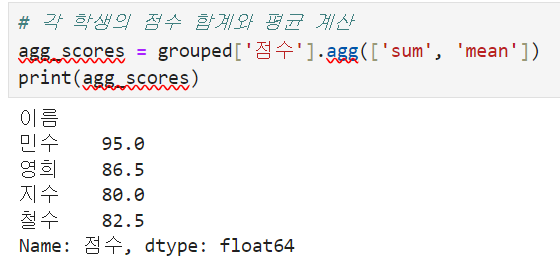
*agg() -> used when using multiple functions
2. pivot_table -> summarize the data, and re-frame base on the standard
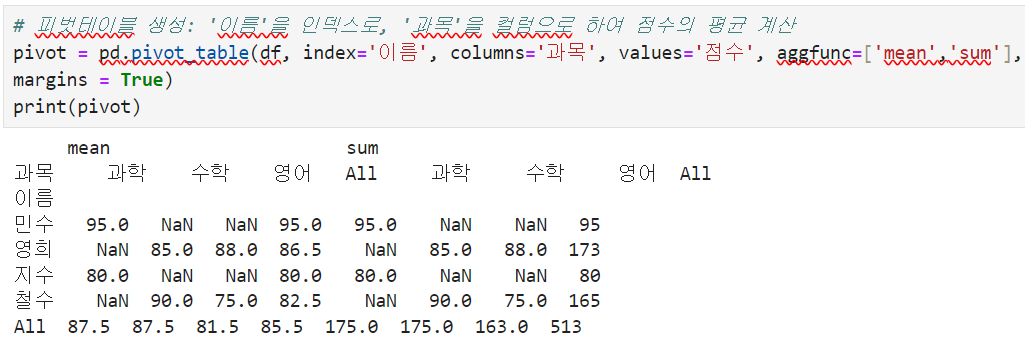
As I can see here index = '이름', columns = '과목', values'점수' then what are the aggfunc?
It shows all the function results based on what's in the []. That is why there are two tables named mean and sum. and the margins will calculate base on what's in the []. there are 2 options. mean and sum. In the mean table, the margin will get only the average of the columns, but in the sum table, it will only get the sum of the columns.
Remember I can also set the name of the table.