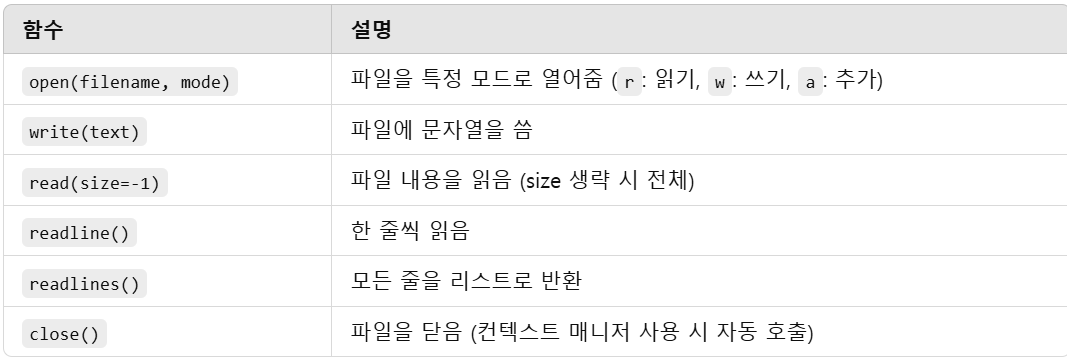
오늘의 개념FlipAnimatornormalized Flip은 간단히 반대편으로 이미지를 돌리는 것,public class Player_movement : MonoBehaviour{ Rigidbody2D rigid; SpriteRenderer render; public float maxSpeed; Animator anime; // Start is called before the first frame update void Awake() { rigid = GetComponent(); render = GetComponent(); anime = GetComponent(); } void Update() { i..